Three repositories, three AI agents, one continuous loop — generating tests from requirements, writing automation code from plain English, classifying CI failures, and fixing broken locators autonomously. Engineers review a PR at the end. They don't do all the work in the middle anymore.
The System at a Glance
Three repos, each with a distinct responsibility. AI Test Studio is the browser interface engineers open. It proxies agent requests to QA Agent Network — the AI backbone running three independent Claude-powered agents. Both read from and write to Jarvis, the Java/Maven automation framework where all generated test code lives.
Five Features. One Closed Loop.
Each feature is a standalone workflow. Together, the output of one stage feeds the next — closing the loop from requirements all the way to verified, self-healing automation.
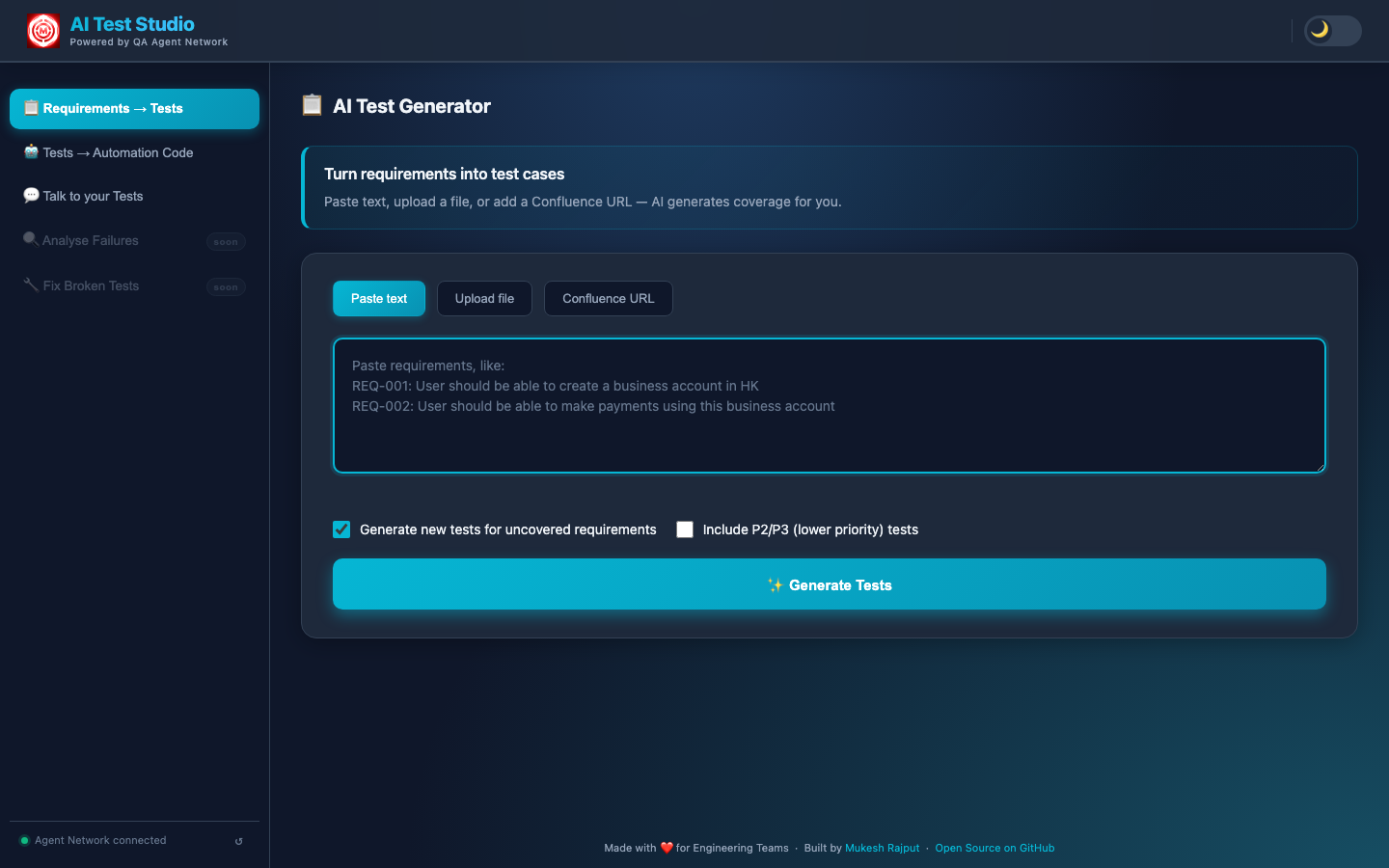
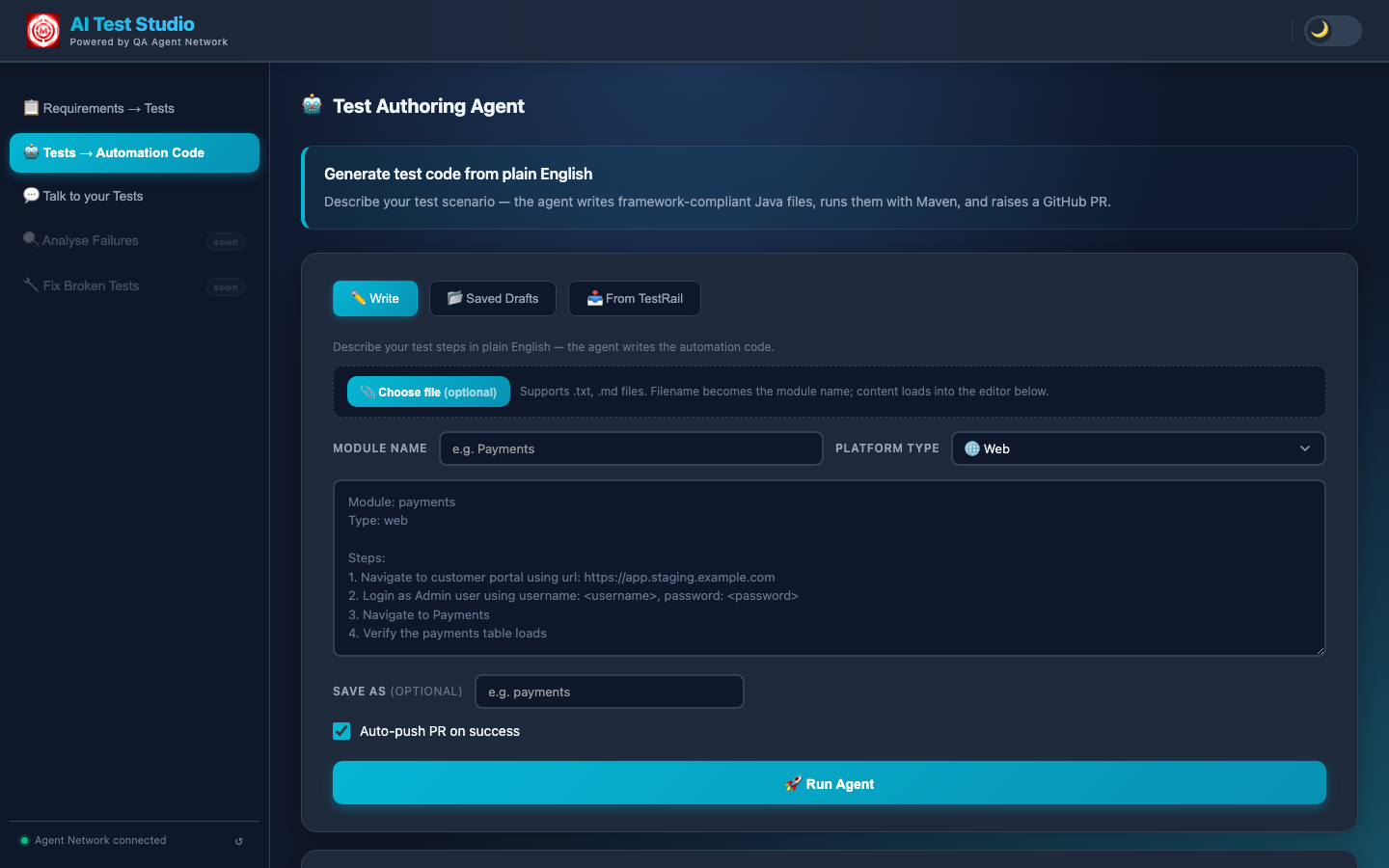
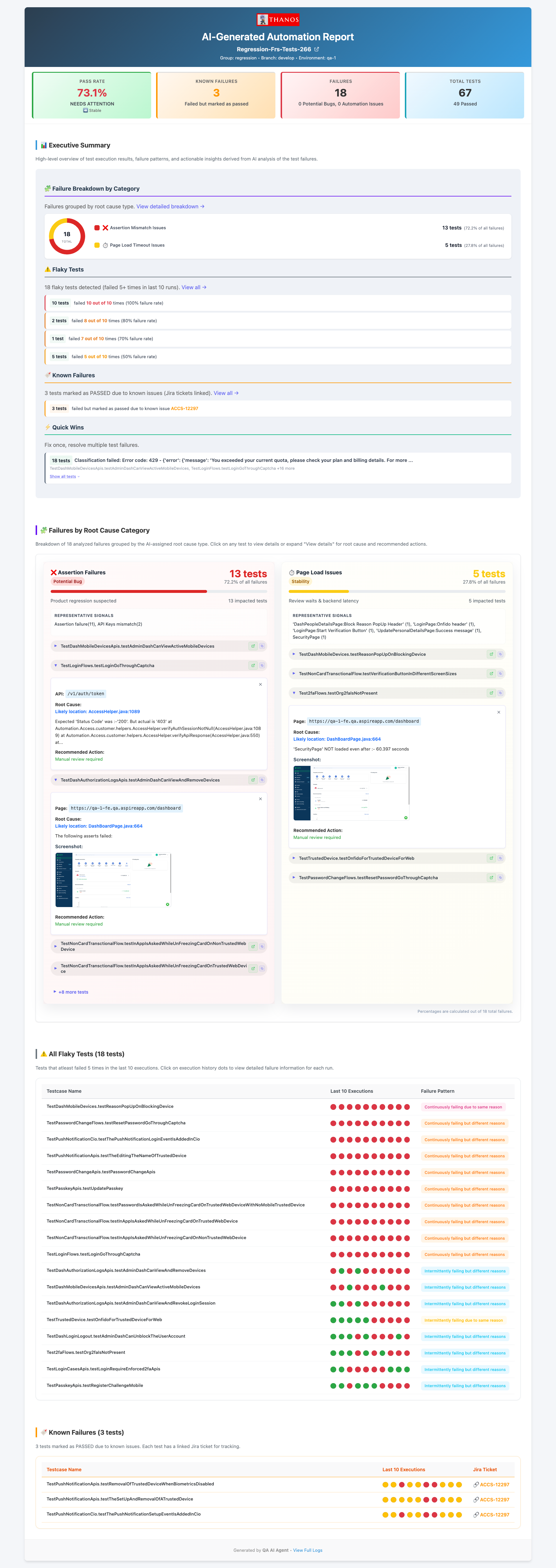
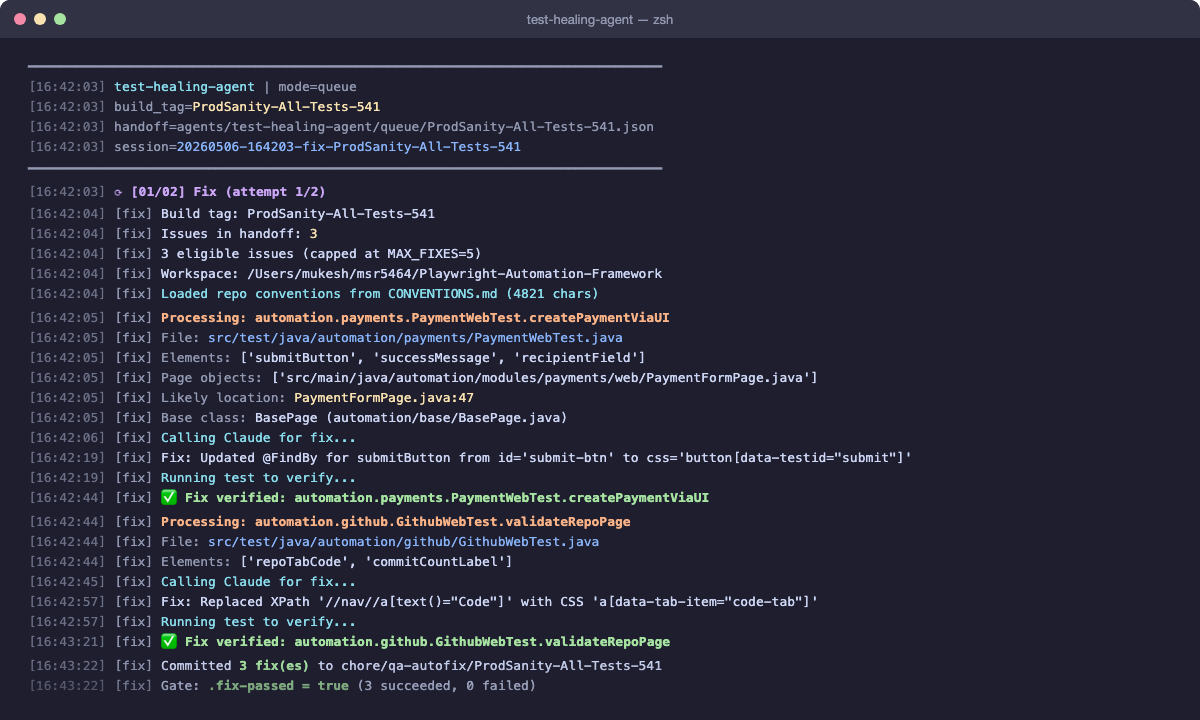
The Closed Loop
CI runs → failures to MySQL → Triaging Agent classifies → Healing Agent fixes Automation Issues → PR raised → engineer merges → next CI run passes
Real Numbers From Production
The Key Design Insight: CLAUDE.md
Every AI agent reads one file before doing anything: Jarvis/CLAUDE.md — a plain-text conventions file defining every naming rule, class pattern, and DO/DON'T for the Java framework.
Why this matters
Change the framework → update CLAUDE.md → every agent adapts on the next run. No prompt engineering buried in Python scripts. The conventions live in the repo, version-controlled and reviewable alongside the code itself.
What We Learned Building This
A well-maintained conventions file in the target repo is what keeps all agent output aligned with your codebase. Invest here before you invest anywhere else in prompt engineering.
A single model classifying 50 CI failures will make confident mistakes. Running a second model as an independent reviewer with structured debate rounds catches those mistakes before they reach the report.
When the healing agent can't fix a test, it still raises a PR with a NEEDS-REVIEW verdict — full context of what failed, what Claude tried, and why. Engineers fix it in minutes instead of starting blind.
Confirming selectors against the real staging environment before generating code eliminates an entire class of first-run failures. The extra 2–3 minutes upfront saves 10+ minutes of debugging downstream.
Tech Stack
Explore each feature in depth
All three repos are open source. Each feature has a full deep-dive page covering the implementation, pipeline steps, screenshots, and design decisions.